
Bringing Data to the Cloud
I lead a team of engineers here in the London Pivotal office, who are responsible for building the next generation of Data Services for Pivotal CF. Here's some of our thinking around building reliable, self-sustaining, dynamically provisioned data services.
Bringing data services to a platform like Cloud Foundry is absolutely key. Building a production-grade PaaS is by no means easy, but superficial stateless platforms are becoming commodities. This is a good thing - it's the progress driving agility and the DevOps movement. However, everything changes when you add state.
Managing stateful processes, juggling volumes, managing backups, ensuring uptime, gardening AOFs and snapshots, dealing with startup dependencies… It's hard. And doing all of this in a completely automated way, behind unknown firewalls, in unknown environments is crazy-hard. However, we have a secret weapon which moves this problem just out of "insane" and into merely "ill-advised."
Challenges
We have a lot of services to build for 2014 - Cassandra, Redis, Neo4j, MongoDB, Memcached, Elasticsearch, and more. Because of this, we're forced to look at deploying and managing services from a much more holistic point of view. We have to concentrate on building patterns that can be reproduced instead of bespoke snowflakes.

Also, because we're building Cloud Foundry Services, we have the added complexity of building these to be provisioned on-demand - either as multi-tenant or single-tenant instances.
Cloud Foundry Services API
Because services that work with the Cloud Foundry platform must provide databases to many different application developers, they need to be able to perform two important actions:
- Create a new instance.
- Return a binding to that instance.
The most important question you have to answer when building a new service is: Exactly what is "an instance?" This informs the rest of your service design, and is the most important aspect of the application developer's experience. There are roughly two paths to go down: Multi and Single-tenant. Of course, the Devil is in the details.
Multi-tenant Cluster
By far, the easiest path is building a multi-tenant service. In the multi-tenant scenario, we deploy a single service cluster which is shared amongst all of the application developers. This basically pushes all of the scaling and resource isolation down into the service itself.
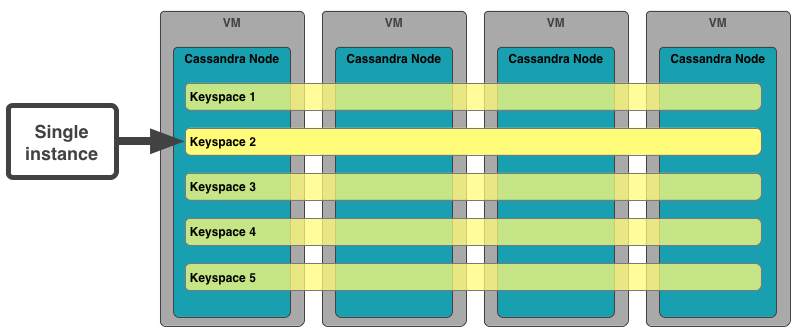
Some services handle this well. MySQL and PostgreSQL are examples of services that work fairly well from a multi-tenant point of view. While they're difficult to scale horizontally, and they don't deal well with noisy neighbors, they do have good authorization and authentication.
Cassandra is another example of a service that can work in a multi-tenant environment. It scales very well horizontally, and has strong authentication. However, there are still issues with its authorization system, and it has no good way of dealing with noisy neighbors.
Single-tenant Processes
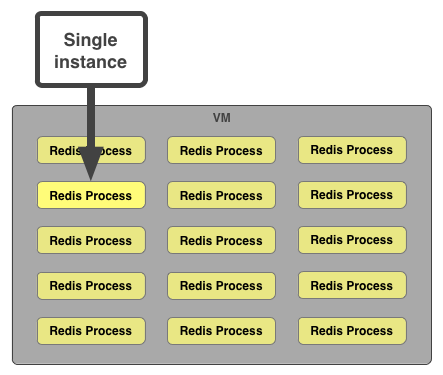
Some services, however, don't work at all in a multi-tenant environment. Redis is such a service - it has no multi-user authentication or authorization, and it doesn't yet scale horizontally. Furthermore, its single-threaded, single-process architecture makes it extremely sensitive to noisy neighbors.
For services such as this, it's better to provision dedicated processes for each requested instance. While the VM is still shared amongst users, because users get a dedicated process, we categorize these as single-tenant.
Security with Single-tenant services is much easier. However, now we have to deal with real-time provisioning, configuration and orchestration. We have to keep hundreds of dynamic processes running, and we have to upgrade each of them when a new release is deployed. Each process has its own directory for persistent storage, which needs to be baby-sat during this whole process. And we still haven't solved the noisy neighbor problem, since a single process could hog a single CPU or all of the available IOPS on the VM.
Single-tenant Clusters of Processes
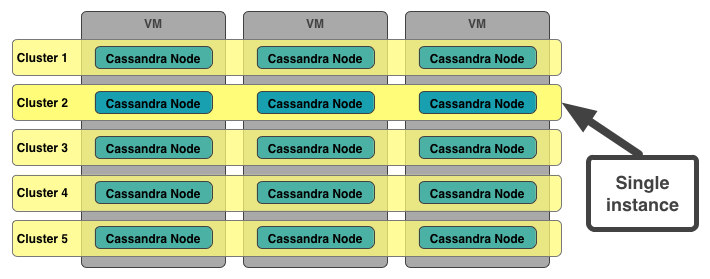
The difficulty of provisioning and orchestrating these processes becomes much greater when we need to scale out horizontally. Now we need to manage clusters of processes across multiple VMs. We must migrate processes when VMs are removed, maintain state across VMs, control the boot-sequence, manage master/slave IPs, etc. For this, we need some level of process scheduling - likely using our own diego.
Containers

Wrapping each process in a Docker container seems like a no-brainer at first glance. This solves the noisy neighbor problem, and adds another layer of security around the service. It certainly is a good idea, but it's also not trivial. Docker hasn't yet figured out the software-defined-networking problem. It also doesn't solve the issues around stateful services and inter-VM data migrations.
Single-tenant Clusters of Virtual Machines
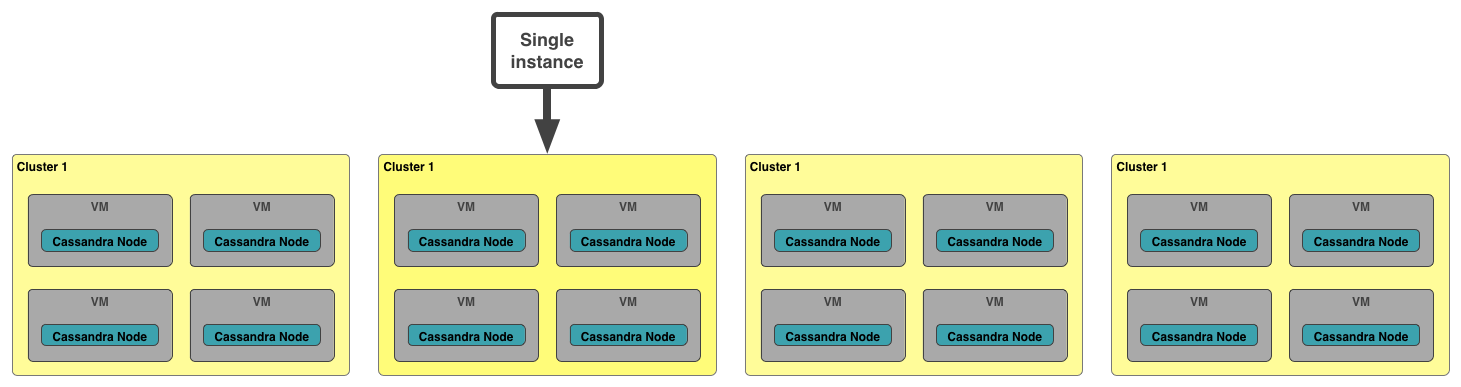
Once we start getting into real production workloads, splitting up VMs via processes or containers becomes a non-starter. Production workloads require all of the resources available on the VM.
While BOSH (our large-scale deployment tool of choice) is generally geared towards static deployments, we can use it to dynamically spin up entire dedicated clusters of VMs when an application developer asks for an instance of a service. The processes running on those VMs may also be containerized, if only for consistency and another layer of security, but the VMs are dedicated to a single instance. There are no more noisy neighbor problems, and the cluster can make full use of the CPU, IOPS, and network.
Still Exploring
This is exactly the topic that Chris Brown and I spoke about at the 2014 Cloud Foundry Summit. You can find the video here.
To be clear, this is still all very much a work in progress. We're constantly exploring new and improved ways of tackling this challenge, and we fully expect to get it wrong before we get it right. It's a process that's just as fulfilling as it is challenging.
If this sounds exciting to you and you’re interested in joining the London Services team, I’d love to hear from you!